두 변수 값 바꾸기에 대한 고찰: 후속편
TL;DR: 스왑 함수는 임시 변수 또는 XOR 연산으로 구현할 수 있다. 이 둘의 미시적인 차이는 설명할 수 있다. 그러나 스왑 함수가 인라인 및 최적화 된다면 (추가) 그리고 스왑된 변수가 값으로 사용되어 레지스터로 승급이 된다면 두 방법에는 아무런 차이가 없다. LLVM 기준으로 인라인 후, 임시 변수 스왑에 memory to register promotion 또는 Scalar Replacement Of Aggregates (SROA) 최적화를, XOR 스왑에 instruction combine 최적화를 적용하면 이 둘의 차이는 없어진다.
(추가) 한편 스왑된 변수가 메모리에 상주해야할 때는 컴파일러에 따라 XOR/임시 변수 방식에 따라 차이가 발생할 수 있고, 일반적으로 임시 변수 방식이 보다 더 최적화에 용이하다고 말할 수 있다.
두 변수 값1을 서로 바꾸는 스왑 함수는 보통 임시 변수를 써서 만든다. 아래 같은 전산학 유머도 있다.
프로그래밍 유머 해주세요 — 전산과 학생 두 명이 자리를 바꾸는 데 필요한 의자의 갯수는 세 개입니다. http://t.co/M9kRPVwW5G
— Jeong Jinmyeong (@BaalDL) September 2, 2014
그런데 임시 변수를 쓰지 않고 XOR 산술 연산만으로 바꾸는 방법도 널리 알려져있다. 덕분에 임시 변수를 안 쓰는 스왑 함수가 더 효율적인지 종종 논쟁이 되곤 한다. 무려 9년 전, 이 두 스왑 함수의 구현 방법을 컴퓨터 구조 관점에서 비교하였다. 6년 전 출간된 拙著에서도 이 주제로 한 단원을 썼다. 긴 세월이 지난 지금, 다시 한번 임시 변수 스왑과 XOR 스왑의 차이에 대해 정리하고자 한다. 당시 제대로 이해 못 했던 것을 이제서야 알게 되었다.
임시 변수 스왑과 XOR 스왑 비교
비교하고자 하는 두 스왑 함수의 C++ 구현은 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
void temp_swap(int& a, int& b) {
int temp = a;
a = b;
b = temp;
}
void xor_swap(int& a, int& b) {
a = a xor b;
b = b xor a;
a = a xor b;
}
이전 블로그 글이나 책의 내용을 요약 정리하면 대략 이러하다. 이 부분은 건너 뛰어도 좋다.
temp_swap은 임시 변수 temp를 쓰므로 메모리 접근이 더 필요할 것 같다. 하지만 매우 특수하고 예외적인 환경만 아니라면 컴파일러는 최적화를 하여 temp 변수를 메모리에 할당하지 않고 레지스터에서 처리한다. 추가적인 메모리 사용이나 접근은 없다.
반면, XOR 방식은 임시 변수가 없으니 빨라 보이지만 꼭 그러한 것은 아니다. 명령어 사이의 의존성을 살펴봐야 한다.
라인 8-10에 있는 세 연산 사이에는 반드시 지켜야 하는 의존성이 있다. 이 의존성은 RAW(Read-After-Write), 다른 말로 흐름 의존성(flow dependency)으로 불린다. 라인 8의 연산을 끝내야만 라인 9를 수행할 수 있고, 마찬가지로 라인 10도 라인 9의 결과를 기다려야만 한다. 이 의존성으로 xor_swap의 세 XOR 연산은 동시에 수행될 수 없다. 전문 용어를 빌어 쓰자면 명령어 수준 병렬성(ILP, Instruction-Level Parallelism)이 없다고 말한다. 모바일을 포함한 현대 CPU는 ILP를 최대한 활용하도록 설계되어있다. xor_swap은 이런 CPU의 강점을 누릴 수 없다.
temp_swap의 연산에도 의존성이 있다. WAR(Write-After-Read), 또는 반 의존성(anti-dependency)이다.
하지만 WAR 의존성은 RAW 의존성과 다르게 회피할 수 있고 명령어 수준 병렬성을 얻을 수 있다.
코드 1의 라인 2-3에 변수 a는 WAR 의존성이 있다. 라인 2에서 a를 읽은 다음 라인 3에서 쓴다.
그런데 코드 2처럼 a를 a_을 바꾸면 이 WAR를 없앨 수 있다. 이렇게 하면 코드 2의 라인 1과 2는 서로 의존성이 없고 동시에 실행할 수 있다.
xor_swap은 세 연산이 모두 순차적으로 실행되어야 했다면 temp_swap은 두 연산을 한 번에 처리할 수 있으므로 임계 경로 길이를 하나 줄인다. ILP를 얻은 것이다.
1
2
3
int temp = a; // 라인 1과 2는 동시에 수행 가능
a_ = b; // 변수 a 사용처를 모두 a_로 바꿔야 함
b = temp;
그런데 실제 코드에서도 차이가 있을까?
미시적인 관점에서 이 두 구현 방법은 이렇게 설명할 수 있다. 미세하지만 성능 차이도 측정 가능할 것이다. 그렇지만 실제 코드에서 두 방법에 차이가 있는지가 사실 더 중요하다. 예전 글에도 이런 의문지 있었지만 답을 제대로 찾지 못 했다. 이후 좀 더 컴파일러를 들여다 보면서 답을 찾을 수 있었다. LLVM 도구로 컴파일 최적화 과정을 하나씩 적용해가면서 살펴보자.
LLVM 도구로 컴파일 과정 이해하기
LLVM에 대한 설명은 생략해도 될 것이다. 요즘은 그냥 clang으로 자주 접한다. 예전 글이라 오류가 있을 것 같아 두렵지만 5년 전에 쓴 LLVM에 대한 짧은 소개 글을 참고 해도 좋다.
사용자는 clang hello.c -O3 -g -o a.out처럼 컴파일러를 쓴다. 이 간단한 명령에 여러 과정이 숨겨져있다. 현대 컴파일러는 소스 파일 하나를 보통 세 단계로 처리하고 마지막에 링킹 또는 JIT(Just-in-time)을 한다.
- 프런트 엔드: 소스 코드를 읽어 구문 분석을 한 뒤 중간 표현(IR, Intermediate Representation)으로 변환.
- 미들 엔드: IR에서 여러 최적화 수행.
- 백 엔드: 최적화된 IR를 해당 기계어로 변환. 실행파일이 목표면 오브젝트 파일 생성, JIT는 메모리에 준비.
- 링크: 실행파일 생성이라면 링크 시간 최적화 및 최종 실행 파일 생성, JIT는 코드 실행.
LLVM에서는 이 과정을 LLVM 도구로 하나하나 조작할 수 있다. 아래 그림은 clang -O3 hello.c가 어떻게 내부적으로 처리되는지 보여준다. 그림 중 clang, opt, llc, lli는 LLVM 도구이며 as와 ld는 GNU binutils에 있는 어셈블러와 링커이다.2
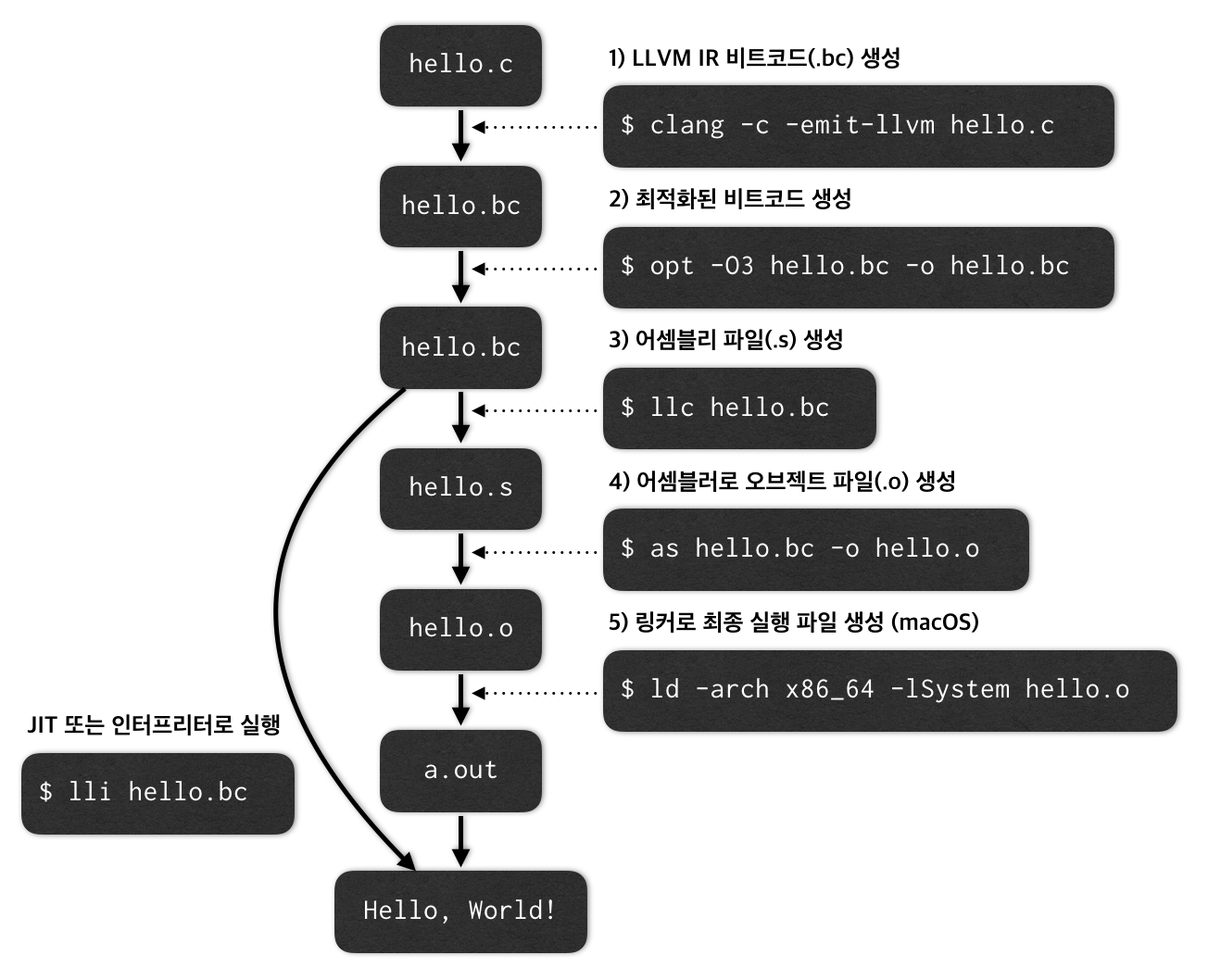
-emit-llvm옵션으로 소스 코드를 LLVM IR인 비트코드 파일(.bc)로 변환한다.llvm-dis로 사람이 읽을 수 있는 비트코드로 해독할 수 있다.opt는 비트코드 파일을 대상으로 각종 최적화를 할 수 있다. 그림에는-O3처럼 간단히 줬지만 매우 세밀하게 컴파일러 최적화 옵션을 줄 수 있다. 곧 알아볼 것이다.- 최적화가 끝난 비트코드를 x86이나 ARM 같은 어셈블러 코드로 변환해야 한다.
llc라는 백엔드 컴파일러가 IR를 기계어로 낮춘다.hello.s는 사람이 읽을 수 있는 어셈블러 코드이다. - 어셈블러 코드부터는 GNU binutils가 그 임무를 수행한다. 먼저 GNU 어셈블러인
as가hello.s를 읽어 오브젝트 파일로 변환한다. - 마지막으로 링커인
ld가 필요한 시스템 라이브러리와 묶어 최종 실행 파일을 만든다. lli라는 LLVM JIT/인터프리터로 비트코드 파일을 바로 실행할 수도 있다.
관심있는 분을 위해 LLVM 도구 설치 법을 소개하자면 맥에서는
brew install --with-clang llvm로 간편히 된다. LLVM 도구는/usr/local/opt/llvm/bin에서 찾을 수 있다. 직접 컴파일하는 것도 그리 어렵지 않아서 추천한다. LLVM 깃 미러에서 다운 받아 ninja로 빌드하면 좋다. 윈도우에서는 비주얼 스튜디오로도 할 수 있다.
opt로 스왑 함수의 차이 확인하기
준비 과정이 좀 길었다. 먼저, 테스트에 쓸 코드는 기막힌 온라인 컴파일러에서 볼 수 있다: https://godbolt.org/g/LA4T1h.
스왑 함수는 템플릿으로 바꿔봤고 테스트 함수에서는 temp_swap과 xor_swap을 각각 한 번씩 부른다.
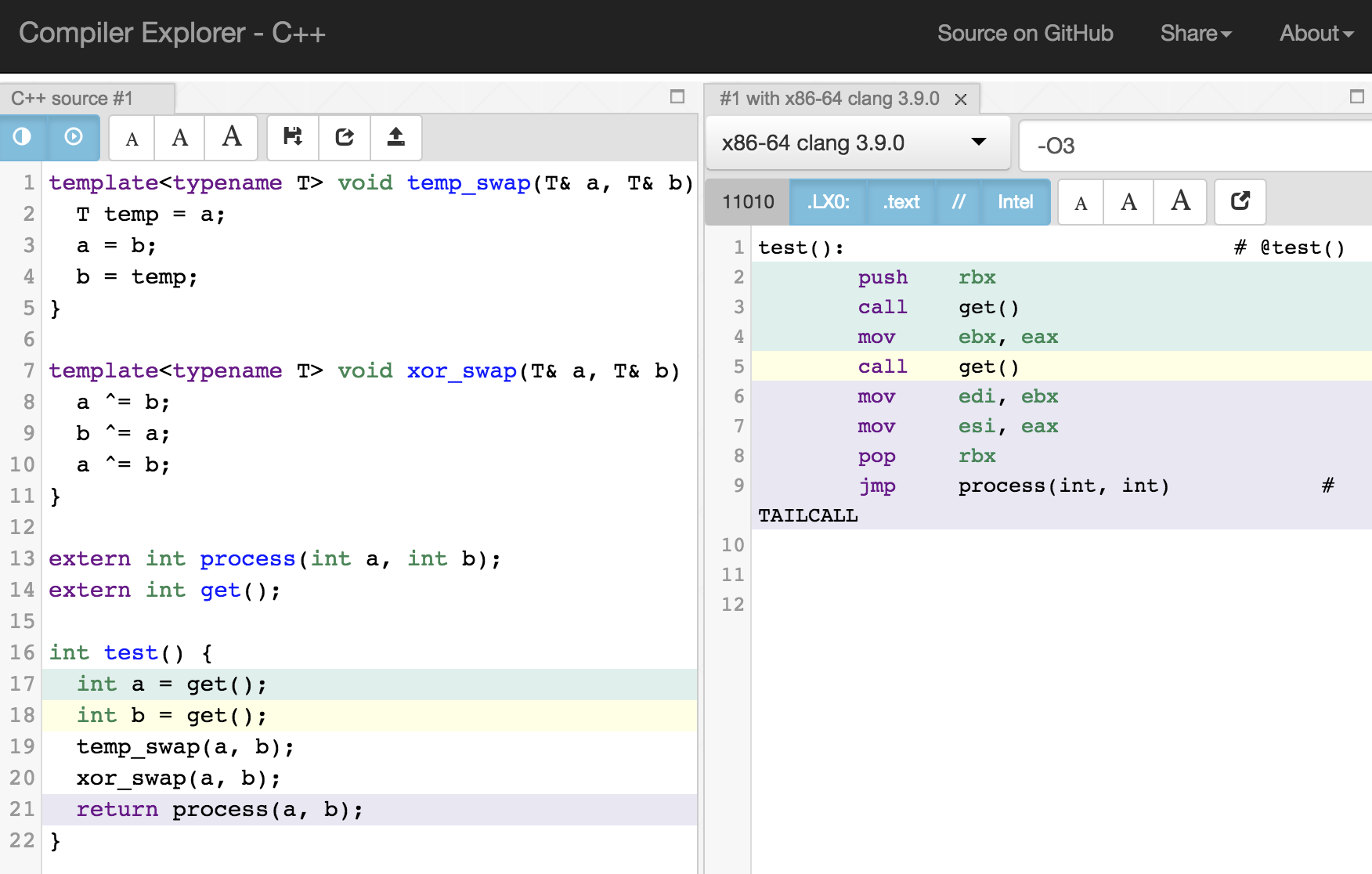
글 시작 요약에서 이미 말했지만 위 그림을 보면 temp_swap이던 xor_swap이던 -O3 최적화에서는 아무런 차이가 없다. 심지어 스왑 함수 코드는 모두 지워졌다.
-O3 최적화는 185개의 최적화 패스를 거친다.
이제 본격적으로 LLVM 도구 opt를 이용해 도대체 어떤 최적화가 위 같은 코드를 만들어 냈는지 찾아본다.
약간 거짓말을 했다. 최적화에 대한 아무런 사전 지식이 없다면, 185개 최적화를 이진 탐색으로 찾아가며 그 변화를 찾아야 한다. 매우 지루할 것이다. 여기서는 어느 정도 최적화 루틴에 대한 지식을 기초로 바로 찾는다.
준비물: 최적화 안 된 비트코드 준비하기
테스트 코드 swap.cpp로부터 최적화가 전혀 안 된 비트코드 swap.bc를 얻어 내자.
$ pwd
/Users/minjang/code/llvm/build/bin
$ ./clang++ -c -mllvm -disable-llvm-optzns -emit-llvm -o swap.bc swap.cpp
$ ./llvm-dis swap.bc그런데 뭔가 이상한 옵션 하나가 보인다: -mllvm -disable-llvm-optzns. 최적화 옵션을 안 줬으니 최적화 안 된 비트코드가 나와야하겠지만, 프런트 엔드에서 IR 차원의 최적화가 있을 수 있다. 이 괴상한 옵션은 모든 최적화 옵션을 끄도록 한다. 이번 스왑 코드는 간단하므로 이 옵션의 여부에 따라 결과 차이는 없다.
swap.bc는 바이너리 파일이라 사람이 읽을 수 없으므로 llvm-dis로 텍스트로 바꾼다. swap.ll이 생성될 것이고
여기서 볼 수 있다. 길어서 직접 붙여 넣지는 않았다. 이 글에서 LLVM IR까지는 설명할 수 없지만 대충 직관적으로 이해할 수 있다. 최적화가 전혀 안 되었으므로 로컬 변수들이 모두 alloca로 메모리 할당 되어있고 접근은 load와 store로 이뤄지고 있음을 볼 수 있다.
첫 번째 최적화: -mem2reg: Promote Memory to Register
먼저 거추장스러운 메모리 접근을 레지스터로 승급(promotion)하는 최적화인 mem2reg를 수행한다. 여기서 말하는 레지스터는 x86/ARM의 제한적인 레지스터가 아니라 LLVM IR의 무한한 가상 레지스터이다. 이렇게 모든 변수를 레지스터에 있다고 가정하는 것이 훨씬 쉽게 최적화 알고리즘을 구현할 수 있다. mem2reg 최적화를 수행하면 이해하기 쉬운 코드를 얻을 수 있다.
참고로 과거에는 mem2reg 최적화가 별도로 있었으나 요즘은 SROA(Scalar Replacement of Aggregates) 최적화의 일부로 수행된다. -mem2reg 대신 -sroa 옵션을 줘도 이 예에서는 같다.
$ ./opt swap.bc -mem2reg -o swap.opt.bc && ./llvm-dis swap.opt.bc무엇보다 두 스왑 함수의 임계경로 길이가 다름을 확인할 수 있다.
temp_swap은 두 레지스터 %0과 %1에 RAW 의존성을 가진다.
xor_swap은 반면에 세 개의 레지스터 %xor, %xor1, %xor2에 RAW 의존성이 있다.
여기서 라인 15-16, 19-20을 보면 불필요한 중복이 보인다. 값을 저장 후 바로 다시 읽는다. 이 부분을 중복 제거한다면 보다 쉽게 RAW 의존성을 확인할 수 있다.
중복 제거의 대표적인 최적화로 GVN(Global Value Numbering)이 있다. -gvn을 줘서 그 효과를 살펴볼 수 있다.
$ ./opt swap.bc -mem2reg -gvn -o swap.opt.bc && ./llvm-dis swap.opt.bc보다시피 불필요한 store/load를 제거하니 %xor, %xor1, %xor2의 RAW 의존성이 잘 드러난다.
이렇게 temp_swap과 xor_swap의 미시적인 차이를 직접 볼 수 있다.
두 번째 최적화: -inline: Function Integration/Inlining
인라인은 매우 중요한 최적화다. 인라인은 코드 크기를 늘리는 부작용이 있을 수 있지만, 특히 객체 지향이나 JS/루비/파이썬 같은 동적 언어에서 아마도 가장 성능을 극적으로 올리는 최적화일 것이다. 스왑 코드에서도 인라인은 필수다. 인라인을 적용해보자.
$ ./opt swap.bc -mem2reg -gvn -inline -o swap.opt.bc && ./llvm-dis swap.opt.bc인라인은 정말 함수 내용을 복사해서 붙여 넣기한다. 코드를 찬찬히 살펴보면 레지스터 이름만 밀려졌고 그대로 복사/붙이기가 된 것을 확인할 수 있다.
세 번째 최적화: 또 다시 -mem2reg/-sroa로 temp_swap 제거하기
인라인까지 한 결과를 보면 여전히 alloca와 로드 스토어가 보인다. 한번 더 -mem2reg 또는 -sroa를 적용해보자. 그 결과는 약간 놀랍다.
$ ./opt swap.bc -mem2reg -inline -mem2reg -o swap.opt.bc && ./llvm-dis swap.opt.bc보다시피 메모리 연산을 레지스터로 승급하는 과정에서 temp_swap은 사라지고 a, b가 사용되는 곳을 바로 바꾸었다.
마지막 최적화: -instcombine: Instruction Combine으로 xor_swap 제거하기
이제 xor_swap이 어느 최적화로 사라지는지만 알아내면 된다. 정답은 instruction combine이라는 최적화다.
말 그대로 컴파일 시간에 같은 결과를 내는 더 간단하고 더 적은 명령어로 바꾸는 최적화이다. 이 최적화의 코드 양은 상당히 많고 여러 번 불린다. 대표적으로 산술 연산의 교환/결합/분배 법칙을 이용해서 최대한 줄인다.
연산의 특성도 이용한다. A ^ 0 = A 같은 항등식이 한 예이다.
xor_swap의 세 XOR 연산도 이 최적화로 축약이 가능하다. 아래 코드의 주석처럼 차례차례 삭제된다. 디버거로도 이 행동을 정확하게 확인할 수 있다.
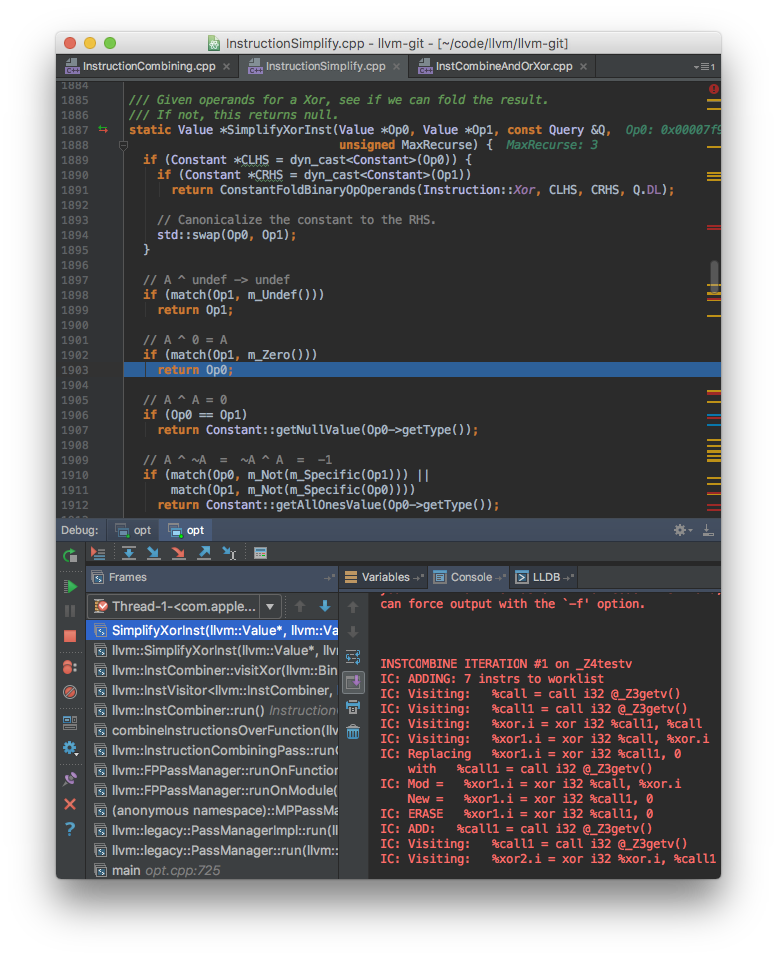
결과적으로 스왑 함수는 모두 사라지고 변수 a, b가 최종 사용처에서 필요하다면 직접 바뀐 채로 전달된다. temp_swap 또는 xor_swap, 수백번을 부르던 아무런 상관이 없다. 홀수 번 불려지면 두 변수가 뒤 바뀌어서, 짝수 번 불려지면 그대로 전달된다.
최적화 이전의 코드와 비교하면 그 차이가 확연하다.
추가 실험
김우승님께서 댓글에서 알려주셨습니다. 앞선 실험들은 스왑된 변수 a, b가 모두 값으로만 사용되어 레지스터로 승급된 경우를 가정했습니다. 하지만 이 변수가 참조 혹은 포인터로 사용되거나, 레지스터가 부족해 레지스터 승급이 안 될 때는 이 변수를 명시적으로 메모리에 할당해야 합니다. 예를 들어, 이 변수를 사용하는 process가 process(int&, int&)로 되면 컴파일러에 따라 xor_swap과 temp_swap의 차이가 발생할 수 있음을 확인했습니다. 변수 a, b를 완전히 레지스터로 승급하지 못하고 명시적으로 스택 메모리에 할당해야하므로 이 과정에서 컴파일러마다 꽤 다른 결과를 낼 수 있습니다. 확인한 결과는 이러합니다:
- clang의 경우
xor_swap과temp_swap방식 모두 차이는 없었습니다만, 짝수번 불리었을 때와 스왑이 한번도 안 불렸을 때는 차이가 있었습니다: https://godbolt.org/g/kAJZ1t - gcc 7.0 미만인 경우
xor_swap과temp_swap에 따라 차이가 발생합니다.temp_swap방식이 훨씬 최적화가 잘 되고xor_swap은 XOR 연산을 남기기도 합니다: https://godbolt.org/g/GW2uNX - 하지만 gcc 7.0은 가장 뛰어난 결과를 이 실험에서 보여줍니다. XOR/임시 변수 방식이던 상관이 없고, 스왑을 짝수번 하면 스왑을 전혀하지 않는 코드와 같은 결과를 냅니다: https://godbolt.org/g/vaPn2I
gcc 7.0 이전에서는 스왑된 변수가 메모리에 명시적으로 할당이 되어야 한다면 xor_swap이 보다 비효율적임을 보았습니다. temp_swap이 최적화 기회를 더 얻을 수 있는 안전한 방법이라고 할 수 있습니다.
결론 (수정됨)
XOR 스왑 함수와 임시 변수 스왑 함수는 적어도 정적 컴파일 언어 언어에서는 인라인만 된다면 차이가 거의 없음을 보았다. 인라인 여부가 훨씬 중요하다. 이런 이유로 C++ 템플릿 기반의 std::swap이나 std::sort 같은 함수가 순수 C 함수 코드보다 더 많은 최적화 기회를 얻을 수 있다. 한편, 스왑된 변수가 메모리 할당이 반드시 필요하다면 컴파일러에 따라 XOR/임시 변수 방법에 차이가 있음을 보았고 일반적으로 임시 변수 방법이 더 낫다고 말 할 수 있다.
이 글에서는 또한 LLVM 도구 사용법과 여러 컴파일러 최적화도 살펴보았다. 요즘 같이 컴퓨터 하나의 성능이 그다지 중요하지 않게된 세상에서는 너무 깊숙한 내용일 수도 있겠지만 관심있는 분에게 도움이 되었으면 좋겠다.