초등학교 덧셈 알고리즘을 코드로 써보기
일러두기
- 이 글은 순전히 저의 개인적인 의견이며 전/현직 회사와는 무관합니다.
- 소개된 문제는 인터넷에서 찾을 수 있는 문제이며 실제 면접에선 변형된 문제를 냈음을 밝힙니다.
- 미국 회사에서 겪은 경험에 기반해 쓴 글이므로 한국 상황과는 다를 수 있습니다.
3줄 요약
- 코딩 면접에서 문제 해결 능력과 코딩 능력은 다릅니다.
- 의외로 사소해 보이는 부분에서도 코딩 능력을 꽤 많이 가늠할 수 있습니다.
- 코딩 면접 준비 시
다이나믹 프로그래밍에 시간 허비하지 말고기초 코딩 능력을 한번 더 점검할 것을 추천합니다.
개발자, 영어로 SWE(Software Engineer)1 또는 SDE(Software Development Engineer)로 대표되는 직업군에 있어 코딩 인터뷰는 필수다. 굳이 이 글에서 코딩 인터뷰가 유용성까지 말하기는 벅차다. 그냥 한 문제를 예로 들면서 코딩 인터뷰의 주요 평가 요소와 실제 지원자들이 어떻게 코딩하는지 이야기를 해볼까 한다. 결국 기본적인 코딩 능력이 중요하다.
코딩 인터뷰의 평가 요소
코딩 인터뷰를 통과하려면 당연히 ‘코딩’을 잘해야 하는데 이 말은 다소 모호하다. 어떤 평가 요소가 있는지 먼저 살펴봐야 한다. 가장 중요한 요소는 “문제 해결 능력”과 “코딩 능력”이다. 이 둘은 언뜻 비슷해 보이지만 확연히 구분된다. 면접관은 이 두 주요 능력에 대한 긍정적 및 부정적 신호를 코딩 면접에서 최대한 많이 찾아낸 뒤 최종적으로 당락을 결정한다.
· 문제 해결 능력
먼저, 문제 해결 능력이란, 예를 들어, “주어진 배열에서 중복된 요소를 제거하세요” 같은 문제가 있다면, 이것에 대한 해법을 논리적으로 설명할 수 있는 능력이다. 적절하고 효율적인 자료구조를 고르고, 알고리즘을 고안해내 면접관에게 설명해야 한다. 기초적인 자료구조와 알고리즘 지식, 전산학 기초 지식, 문제 해결에 대한 창의력 등을 평가할 수 있다. 이 과정에서 코딩이 필요한 것은 아니다.
여기서 코딩 인터뷰에서 문제를 받았을 때 바로 코딩을 시작하는 것이 좋지 않음을 알 수 있다. 아무리 쉬운 문제라도 먼저 면접관에게 접근 방법을 명확하게 설명하는 것이 좋다. 그렇다고 해서 모든 경우를 완벽하게 코딩 전에 설명하라는 것은 아니다. 코드로 옮기다 보면 미처 생각하지 못한 예외 사항을 뒤늦게 발견할 수 있을 것이다. 괜찮다. 하지만 대략적인 접근법은 코딩에 앞서 설명을 해야 한다.
· 코딩 능력
코딩 능력은 이제 제안한 알고리즘을 특정 프로그래밍 언어로 옮겨 쓸 수 있는 능력이다. 문제 해결 능력과는 분명히 다른 요소이다. 매우 기본 코딩 능력인 변수, 조건문, 반복문부터 함수/메서드의 작성 등 말 그대로 코드를 쓰는 과정에서 지원자의 코딩 경험 및 실력을 가늠할 수 있다.
내 경험에 따르면 금융 회사들은 프로그래밍 언어 지식에 대해서도 깊게 평가한다. 하지만 특정 언어 지식 자체는 대게 평가 요소는 아니다. 그래도 시니어급 지원자가 주력 언어의 기본적인 작업, 숫자를 문자열로 바꾸는 방법 같은 것을 잘 모른다면 적어도 나에게는 나쁜 신호이다. 코딩 스타일도 그러하다. 사소한 스타일에서도 몇몇 신호를 찾을 수 있다.
마지막으로 소통 능력, 논리적으로 자기 생각을 얼마나 잘 조리 있게 말하는 가도 중요한 요소이며, 코드를 꼼꼼하게 검증하는 능력도 소홀히 해서는 안 된다.
좋은 코딩 문제란?
참 어려운 질문이다. 코딩 인터뷰 준비로 널리 알려진 릿코드에 가보면 이미 천 개의 문제가 있다.2 좋은 문제도, 이상한 문제도, 나쁜 문제도 있다. 면접관의 철학과 취향에 따라, 또는 회사의 방침에 코딩 문제의 유형이 달라질 수도 있다.
내 생각에 좋은 코딩 문제는 ‘적절한’ 문제 해결 능력과 ‘적절한’ 코딩 능력을 모두 볼 수 있는 문제가 좋다. 적절한이란 단어가 좀 애매하다. 그래서 10명 이상 지원자에게 이 문제를 줬을 때 ‘적절한’ 정규분포가 나오는 문제를 좋은 문제라고 생각한다. 중간 난이도의 문제라면 평균적으로 푸는 사람이 가장 많아야 하며, 못 푸는 사람과 잘 푸는 사람이 비슷한 빈도로 나오면 좋다. 특별히 쉽거나 어려운 문제는 어느 정도 편향이 발생할 것이고 이건 괜찮다.
말이 쉽지 여전히 아리송하다. 한 예로 설명해보자. 나는 다이나믹 프로그래밍 문제를 싫어한다. 면접 문제로 적합하지 않다. 문제 해결이 지나치게 어렵기 때문이다. 미리 열심히 공부하지 않으면 아예 건드리기도 힘들 수 있다. 알더라도 점화식(recurrence)을 찾는 건 굉장한 논리적 도약이 필요하다. 이런 문제는 종형 분포가 나오지 않고 잘 풀거나 아예 못 풀거나로 나뉘어 버린다. 한마디로 A+, A0, D, F 학점만 나오는 일이 벌어진다.
더욱 큰 문제는 문제 해결은 어려운데 코딩은 매우 단순하다는 것이다. 다이나믹 프로그래밍 문제는 보통 테이블에 값만 잘 설정하면 끝나므로 코딩 능력을 깊게 살펴보기 어렵다. 결국 코딩 문제가 아니라 브레인 티저 문제가 되기 쉽다. 이런 이유로 페이스북과 우버 같은 회사에서는 다이나믹 프로그래밍 문제를 내지 않도록 면접관에게 권고한다.
물론 운이 정말 없다면 다이나믹 프로그래밍 문제를 내는 면접관을 만날 수 있다. 코딩 면접에서 운은 사실 굉장히 중요하다. 이럴 때도 겁내지 말고 브루트 포스로 먼저 풀고 메모이제이션 같은 걸로 최적화해도 된다.
다이나믹 프로그래밍으로 태깅된 릿코드 문제는 130개 넘게 있으며, 미국 소프트웨어 개발자들이 꽤 모이는 블라인드 익명 앱에서도 이 문제에 대한 한탄과 고뇌는 흔히 볼 수 있는 주제이다. 여전히 많은 코딩 면접 준비자들이 이걸로 고생하는데 참으로 안타까운 일이다. 나는 과감히 포기할 것을 책임을 지지는 않지만 추천한다. 차라리 다른 기본을 충실히 하는 게 훨씬 좋을 수 있다.
 모 회사의 어떤 회의실 이름
모 회사의 어떤 회의실 이름
오늘의 문제: 문자열로 주어진 두 숫자를 더해보세요.
서론이 너무 길었다. 드디어 제목과 관련 있는 이야기를 해보자. 오늘의 문제는 다이나믹 프로그래밍과 비교한다면 반대편에 있는 문제이다. 즉, 문제 해결 능력은 거의 없거나 간단한 수준이고 대신 코딩을 중점적으로 볼 수 있는 문제이다.
이 문제는 릿코드에도 있으며 43%가 통과한 easy 등급이다.
Given two non-negative integers
num1andnum2represented as string, return the sum ofnum1andnum2.“문자열로 표현된 두 음이 아닌 정수
num1과num2가 있을 때, 이 둘의 합을 반환하시오.
내 생각에 이 정도는 실력 있는 개발자에겐 쉬울 것이다. 스크리닝 인터뷰나 코딩 능력이 다소 부족할 것 같은 면접자에게 변형된 문제를 종종 낸다. 정식 코딩 인터뷰라면 이 문제는 워밍업 문제로 10-15분 내에 풀면 좋다. 그런데 쉽게 생각한 문제에서 생각보다 많은 코딩 능력 신호를 읽어낼 수 있었다. 놀랍기도 하고 한편으론 충격도 받았다. 20-30분씩 걸려서 푸는 사람들도 있었고, 끝내 제대로 완성 못한 지원자도 있었다. 물론 10분 이내에 푸는 사람도 있다.
이 문제에서 문제 해결 능력은 사실상 필요하지 않다. 그렇다. 정말 초등학교 덧셈을 하라는 이야기다. 숫자를 뒤에서 하나씩 읽어 두 합을 구한 뒤 자리 올림수(carry)를 넘겨주는 매우 매우 기본적인 덧셈 이야기다 (그림 출처). 컴퓨터 구조에 나오는 ALU 기본 원리와 같긴 하지만 이 문제는 그렇게 심오한 게 아니다.3
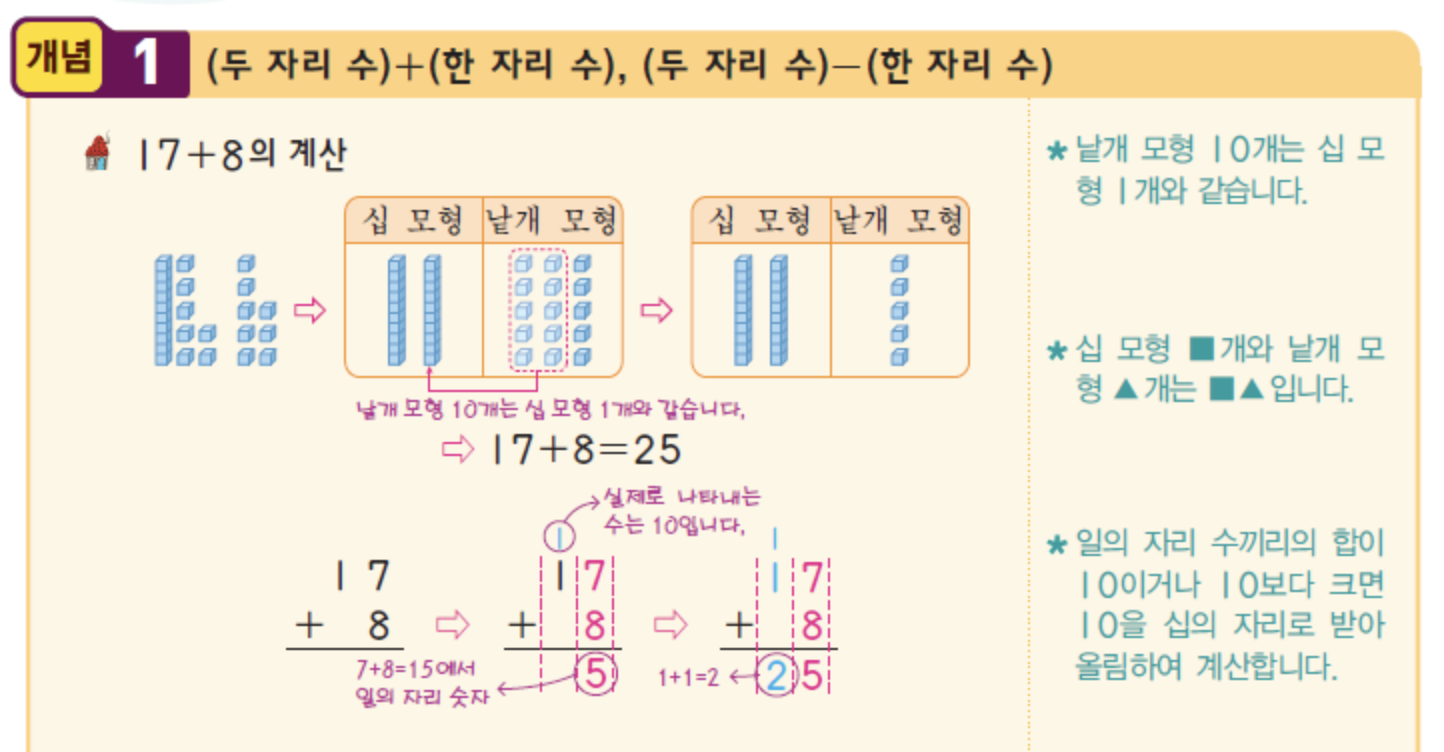
그런데 문제를 이렇게만 주면 의외로 문자열 숫자를 그냥 정수형으로 바로 바꿔서 풀려는 사람이 있다!
def add_strings(a, b):
return str(int(a) + int(b))처음 겪었을 땐 깜짝 놀랐다. 솔직히 말해 코딩 인터뷰의 대부분은 문제를 위한 문제다. 그렇다면 이렇게 간단한 문제를 낼 리는 없지 않은가? 충분히 코딩 인터뷰 연습을 했다면 이런 건 시도조차 하지 않을 것이다. 그런데 이런 시도를 하는 사람이 종종 나온다. 그래서 제약 조건을 말한다. 릿코드 문제에도 이렇게 있다.
You must not use any built-in BigInteger library or convert the inputs to integer directly.
“BigInteger 라이브러리 또는 전체 숫자열을 바로 정수로 변환하는 내장 기능 쓰지 마세요.”
코딩하기
문제 이해가 끝났으니 초등학생이 하는 그 덧셈 알고리즘을 그대로 코드로 옮기자. 차근차근 정리하면 다음과 같다:
- 두 숫자 문자열을 뒤에서 각각 하나씩 읽는다. (입력은 음이 아닌 정수로 가정했으므로 예외 검사는 하지 않아도 된다.)
- 이 두 문자를 숫자로 변환한 뒤에 (‘1’을 1로 변환하는 건 당연히 허용된다) 덧셈을 한다. 올림수를 같이 처리한다.
- 덧셈 결과를 최종 변수에 저장하고, 올림수를 갱신한다.
- 이 과정을 반복한다.
- 반복문이 끝났을 때 여전히 올림수가 있는지 본다. 있으면 1을 추가한다.
여기서 까다로운 부분은 두 숫자 문자열의 길이가 다를 때이다. 상당히 재밌는 것은 이 문제를 푸는 사람마다 이 부분을 모두 제각각의 방법으로 푼다는 점이다. 여기서 여러 코딩 실력을 읽을 수 있다. 사소하다고 생각할 수도 있는데, 변수, 조건문, 반복문을 어떻게 쓰는가는 상당히 중요한 신호이다. 대부분의 코딩은 변수, 반복문, 분기문으로 이뤄진다. 이 문제에서 이런 기본기를 잘 살펴볼 수 있다.
· 파이썬으로 풀기
요즘 인턴, 졸업 예정자, 특히 머신러닝 소프트웨어 엔지니어 지원자들은 대부분 파이썬을 코딩 면접에서 쓴다. 파이썬으로 먼저 생각해보자.
-
두 입력 문자열의 길이가 다른 경우를 처리하는 것이 결국 핵심이다. 정말 다양한 방법이 있는데 나는 왠지 파이선의
zip이 참 맘에 든다. 이 녀석으로 두 입력 문자열에서 문자 두 개를 동시에 읽고 싶다. 그러려면 두 문자열 길이를 맞춰야 한다. 짧은 숫자 앞에다 0을 채워준다. 간단한 작업 같지만, 코딩이 부족한 사람은 여기서부터 여지없이 막힌다. -
zip으로 문자 두 개를 한꺼번에 읽는 반복문을 작성한다. 거꾸로 읽어야 하는데 파이썬 문자열을 뒤집는 건 슬라이스 연산자[::-1]로 하는 게 좋아 보인다. 우아하게x,y를 동시에 읽은 뒤에 덧셈한다.int를 써도 되고 아니면 아스키 코드로 생각해서ord를 써도 괜찮을 것이다. -
여기서 올림수,
carry를 더해야 한다. 이 변수는 미리 0으로 초기회를 해야 한다. 놀라지 마시라. 이 부분 힘들어하는 면접자들이 꽤 있다. 문제 해결 능력이 부족하지는 않을 것이다. 하지만carry를 0으로 미리 잡지 않고 허둥대는 사람들도 있다. 코딩 경험이 부족하면 벌어질 수 있는 일. -
덧셈한 결과가 예를 들어 14라고 하자. 당연히 4만 결과 변수에 저장을 해야 하고 1을 carry로 옮겨야 한다. 자, 여기서도 다양한 코딩을 볼 수 있었다. 분기문을 써서 하던, 나눗셈을 써서 하던 뭐가 됐던 하면 된다. 그런데 모듈로 연산자를 바로 쓰지 못하는 사람도 있다. 12년 전, 굉장한 화제가 되었던 FizzBuzz 문제가 떠오른다.
-
결과를 저장할 때 뒤에다 붙일까(append) 아니면 앞에다 붙일까(prepend)? 그렇다, 여기서도 고민하고 실수하는 사람들이 있다.
보다시피 코드로 옮기는 과정이 생각보다는 조금 까다롭다. 무엇보다 구현의 자유도가 높다. 그러니 다양한 코딩 패턴을 볼 수 있고, 기초 코딩 실력을 파악할 수 있다.
대략 이 과정을 코드로 쓰면 다음과 같다. (참고로 저는 파이썬 전문가가 아니니 제가 쓴 코드가 꼭 좋다는 보장은 없습니다.)
def add_strings(a, b):
if len(a) > len(b):
b = '0' * (len(a) - len(b)) + b
else:
a = '0' * (len(b) - len(a)) + a
result = ""
carry = 0
for x, y in zip(a[::-1], b[::-1]):
sum = ord(x) + ord(y) - ord('0')*2 + carry
result = str(sum % 10) + result
carry = sum // 10
if carry:
result = '1' + result
return result
print(add_strings("12345", "987654321") == "987666666")코딩을 많이 해보지 않은 분들은 길이가 다른 경우 처리를 상당히 힘들어한다. 최악의 코드는 아마도 어느 한쪽이 크다고 가정하고 쓴 코드를 통째로 복사해서 붙여넣는 것이다. 이렇게 하는 분들도 봤다. 파이썬은 언어 특성상 인덱스를 변수로 하는 루프가 흔하지 않다. 그래서 두 문자열에서 동시에 문자를 읽는 것을 척척하지 못하는 면접자들도 간혹 있다.
· C++로 풀기
아무래도 나의 주력 언어가 C++이라서 이걸로도 풀어보자. C++ 코딩 실력을 가늠하는데도 이 문제는 꽤 유용하다. C++은 성능과 관련된 고려가 많다. 코딩 면접 시 코드를 쓰면서도 계속 내가 왜 이 방법을 택하게 되었는지 그 이유를 설명하면 좋다. 짧은 순간마다 자신의 프로그래밍 언어 지식을 말할 수 있다. 파이썬, 자바 등 다른 언어도 마찬가지다.
C++로는 거꾸로 읽는 rbegin()을 이용해면 괜찮을 것이다. 0으로 채우는 번거로운 과정은 피하자. 추가적인 메모리 연산을 굳이 할 필요 없다. 한 쪽이 이미 끝에 다다랐을 때는 0을 주면 된다. 그리고 그냥 C++ 좀 쓴다는 티를 내고 싶어서 stringstream과 reverse를 써보았다. 코드는 이렇다.
string addStrings(string a, string b) {
std::stringstream ss;
auto i = a.rbegin();
auto j = b.rbegin();
int carry = 0;
while (i != a.rend() || j != b.rend()) {
const int x = (i == a.rend()) ? 0 : (*i++ - '0');
const int y = (j == b.rend()) ? 0 : (*j++ - '0');
const int s = x + y + carry;
ss << (s % 10);
carry = s / 10;
}
if (carry != 0) {
ss << 1;
}
std::string ret = ss.str();
std::reverse(ret.begin(), ret.end());
return ret;
}생각만큼 rbegin()을 능숙히 쓰는 사람이 많지는 않다. 그렇다면 인덱스 i, j를 이용하자. 여기서 사소해 보이지만 결코 사소하지 않는 이슈가 있다.
대부분 면접자는 std::string을 포함한 STL 자료구조의 크기나 인덱스를 int로 받는다. 코딩 인터뷰에서는 별문제는 없다. 하지만 STL 자료구조에서 32비트 범위가 넘는 원소 개수를 다뤄보면 int 인덱스가 상당히 눈에 거슬린다. STL은 안타깝게도 unsigned 타입의 size_t를 반환한다. 사실상 서버/데스크탑 컴퓨터는 모두 64비트이므로 64비트 부호 없는 정수가 된다. 다시 말하지만, 인터뷰에서는 그냥 int 써도 충분하다. 그런데 C++ 실력을 더욱 뽐내려면 size_t로 처리하는 것도 좋다.
다만 주의할 것은 size_t로 인덱스를 거꾸로 돌릴 때이다. -1이 되는 순간 무한 루프에 빠지기 때문이다. 그래서 나는 [0, size) 구간에서 반복하되 쓰는 시점에서 인덱스의 역을 구해 쓴다. -1로 종료 조건을 따져야 하는 경우를 원천적으로 피한다.
...
size_t i = 0;
size_t j = 0;
while (i < a.size() || j < b.size()) {
int s = carry;
if (i < a.size()) {
s += (a[a.size() - 1 - i++] - '0');
}
if (j < b.size()) {
s += (b[b.size() - 1 - j++] - '0');
}
...혹시나 수식에 포함된 i++가 눈에 거슬릴 수 있다. 아무 생각 없이 쓰다간 undefined behavior를 만날 수 있다.
결론
이전 회사와 지금 회사에서 대략 100번에 가까운 코딩 인터뷰를 한 것 같다. 여러 코딩 문제를 써봤는데 이 문제는 기본적인 코딩 실력을 확인하는 데 좋다. 이 문제를 잘 푼다고 코딩을 잘한다고 말하기는 힘들다. 하지만 코딩 실력이 부족한 사람은 쉽게 판단할 수 있다. 반대로 말하면, 코딩을 이제 막 시작한 분들에게 이 정도 문제가 쉽게 느껴지면 초급을 넘는 코딩 실력은 갖춰줬다는 뜻이기도 하다.
언제나 기본이 제일 중요하다. 주어진 알고리즘을 코드로 옮기는 기본 코딩 능력이 가장 중요하다. 문제 해결 능력은 그 뒤다. 코딩 중에서도 분기문, 반복문, 변수, 수식 같은 기본기가 탄탄해야 한다. 이런 기본기에 소홀하면 릿코드 문제를 몇백 개 풀어도 코딩 면접에서 떨어질 수 있다.
-
SWE를 ‘스위’라고 미국인들은 보통 읽는다. 충격 받지 않도록 주의. ↩
-
오죽하면 “나 코딩 인터뷰 준비해”를 요즘 “나 릿코드해”라고 말합니다. ↩
-
이 문제를 내 전공(컴파일러, 코드 최적화, 컴퓨터 구조) 관점에서 본다면 arbitrary precision 문제이고 매우 깊게 이야기 할 수 있는 주제이다. ↩